Word2vec: Encoding Meaning with Vectors
- Why Do We Care?
- Encoding Words
- It’s All About Relationships
- Continuous Bag-of-words (CBOW)
- Skip-gram
- Noise Contrastive Estimation (Negative Sampling)
- Did it Work?
- Some Important Takeaways
Why Do We Care?
There are a few things that make encoding the meaning of natural language in computers difficult. Of course, by this I mean something more useful than a dictionary with definitions. We want the information in a format such that we can easily use the semantic information in algorithms on a computer. Example tasks might include finding relevant documents using natural language (as a search engine does), evaluating the sentiment of reviews or even generating new text or images as popular chatbots can. Having a semantic representation of natural language is extremely useful for all of these tasks.
Encoding Words
To begin, let’s consider encoding the meaning of individual words. Of course, words and letters are already represented as numbers in a computer but the semantic relationships are not obvious in this form. For example, it is not clear that hippopotamus and animal are somehow related just by looking at the letters. Somehow our representations should be similar for words with similar meanings and different for words that have different meanings.
It’s All About Relationships
As a child, you were probably taught that you could try to reason about the meaning of an unknown word by considering the words around it. For example, in the sentence I ate a juicy, ___ apple, you would know the missing word is an adjective and one that would usually be associated with apples. Therefore, a good guess would be red and other reasonable guesses might be green or big. You probably wouldn’t guess hippopotamus. And if I gave you more and more examples where the answer was red, you would be able to associate red with its meaning based on the things it is associated with. That is, you know fire can be red, cars can be red, clothes can be red, blood is red etc. In fact, in this way, all of these objects are similar. But how does this help us encode words on a computer?
Well this is where machine learning comes in. We can create a guessing game for a machine learning model. Firstly, we could define a vocabulary (all of the possible words the model knows) and initialise each of the words with a random vector (actually two vectors - one for the target word and one for context). Now we can use a simple neural netowrk to update these embeddings. In the original paper, two methods were presented. The first model used surrounding words to predict the middle word and is known as continuous bag-of-words (CBOW) and the other used the middle word to predict the surrounding words and is known as Skip-gram.
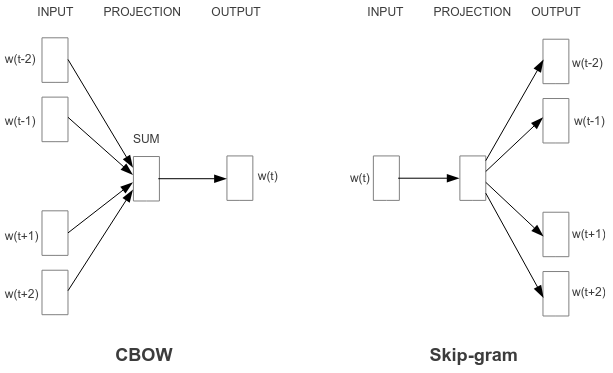 The model architectures for word2vec
The model architectures for word2vec
Continuous Bag-of-words (CBOW)
The continuous bag-of-words method uses the context around a word to guess the missing word. This is achieved by taking the average of the embeddings of each of the surrounding words. This averaged embedding is then used to predict the missing word. For efficiency, this is achieved using a hierarchical softmax structure similar to a Huffman tree that turns predicting the word into a string of binary decisions (each leaf of the tree corresponding to a node). Since this post is not focused on this optimisation technique I won’t describe it any further and instead refer you to this paper on it.
The most important part is that this means the input embeddings can be treated as high dimensional vector representation that takes on some semantic meaning. Since the context word embeddings are averaged, the order does not matter so it is classified as a bag-of-words method. Furthermore, the embeddings are dense high dimensional vectors rather than sparse one-hot encodings and so they can be thought of as a continuous representation. Hence the technique is named continuous bag-of-words (CBOW).
Skip-gram
The skip-gram method performs the opposite task - that is, given an input word, it predicts the surrounding context words. In the first implementation, is given an input word and the label word is sampled from the context words around it. A higher sampling rate is given to words that appear closer to the input word. Once again, it uses the hierarchical softmax technique for efficiency.
Noise Contrastive Estimation (Negative Sampling)
Additionally, there is a follow up to the skip-gram paper which instead uses pairs of words actually from the context and noise samples. The objective of the model is then to distinguish which words are context words and which are noise samples. The dot product of two vectors is considered a similarity measurement since a higher dot product indicates that two vectors point in a similar direction (it is the magnitude of the projection of one onto the other). Therefore, the loss function was directly tied to this measurement of similarity (with a sigmoid applied) such that context words should be similar to the input word with larger dot products and noise words should be dissimilar with larger negative dot products. Further details can be found in the paper.
Did it Work?
So the idea was to encode the meaning of words into vectors. In the follow up paper for the skip-gram model, the authors investigate this by defining an analogy task. The questions would have a format similar to Germany is to Berlin as France is to ___? where the correct answer would be Paris (since it is the capital city of France). To answer this question, the embeddings were calculated for each of the input words and then the output word was calculated by finding the word in the vocabulary that had the highest cosine similarity to the vector,
\[\text{vec("Germany") - vec("Berlin") + vec("France")}\]with the cosine similarity defined based on the dot product of two vectors,
\[\text{cosine similarity} = \cos\theta = \frac{\mathbf{A} \cdot \mathbf{B}}{\lVert\mathbf{A}\rVert\lVert\mathbf{B}\rVert}\]This can be interpreted as defining a vector that points in the direction that has a meaning similar to capital city (vec(“Germany”) - vec(“Berlin”)) and then adding that meaning to the vector for a specific country, France so that the result should be close to the capital city of France, Paris (or in the most similar direction).
The authors visualised this relationship in the following figure,
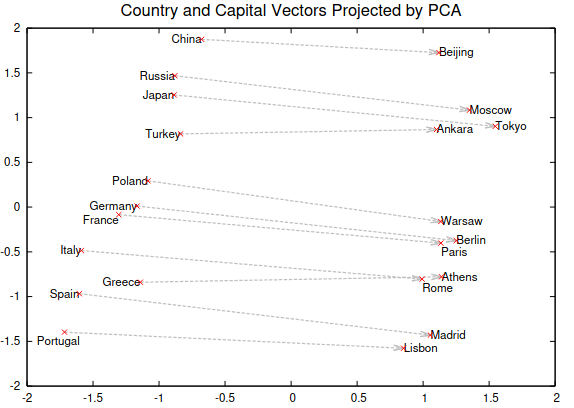 A figure that uses PCA to project the 1000 dimensional embedding vectors into 2D. The directions relating countries to their capital cities are similar
A figure that uses PCA to project the 1000 dimensional embedding vectors into 2D. The directions relating countries to their capital cities are similar
Now the training data never specifically mentioned any information about capital cities so this encoding and the linear structure for meaning in the vectors was learned. So it appears semantics have been encoded into the words.
Additionally, due to this linearity in the structure, sentences or paragraphs can be encoded simply by adding the embeddings of each of the words!
Some Important Takeaways
While word2vec has been mostly superseded by Large Language Models (LLMs) based on the Transformer architecture, dense vector representation of words and sentences to extract semantic meaning are still relevant. In fact, these Transformer architectures appear to learn similar structures for embeddings as well. The main difference then is that the architecture combines words in sentences much more cleverly than to just add the vectors together. The details of this are a topic for another day but suffice it to say that the ideas in this paper are still extremely relevant.
Additionally, I think it’s important to highlight that what made this model work was not a fancy architecture but rather a clever training method. Similar methods have been more recently used for LLMs. In particular, similar techniques were used to train powerful Transformer models such as BERT or even for vision models.
Finally, I want to link to a video that I thought made a very good case for why representing meaning in these high dimensional vector spaces works so well. It feels surprising that there could be so many different directions that can represent so many different meaning that are unrelated to each other. This video explains why high dimensional vector spaces can represent this information so well (particularly towards the end of the video).
Comments powered by Disqus.